本文是 CS336 第一讲的学习笔记,主要介绍开设这门课程的背景和动机,并对课程主要内容做了概览。还介绍了不同的分词器基本原理及其优缺点。
引入
为什么要学习这门课程
现象:研究人员与底层技术越来越远。八年前,他们需要自己实现和训练模型;六年前,他们需要下载一个模型,并进行微调;现如今,他们仅仅修改模型的提示词。
当然,上述现象并不是坏事,通过抽象程度的不断提高,研究人员才得进行更高效地工作。但是,基于 抽象漏洞定律,抽象不可能完美隐藏底层细节。并且,仍有许多基础性的工作亟待开发,这些工作需要对底层有着深入的洞察。
这门课程将通过从头建立语言模型的方式来让大家彻底理解语言模型各个层面的技术。
制约因素
学习现代大语言,有两大制约因素:
- 在大模型工业化时代下,训练一个大模型的成本极高,需要大量的硬件、时间和金钱成本。
- 最前沿模型(GPT 系列)几乎不公开详细的技术报告,缺乏学习材料。
小模型不具备代表性
我们可以通过训练小模型(参数量小于 1B)来弥补上述制约因素,但是小模型的经验并不能完全适用于大模型。
-
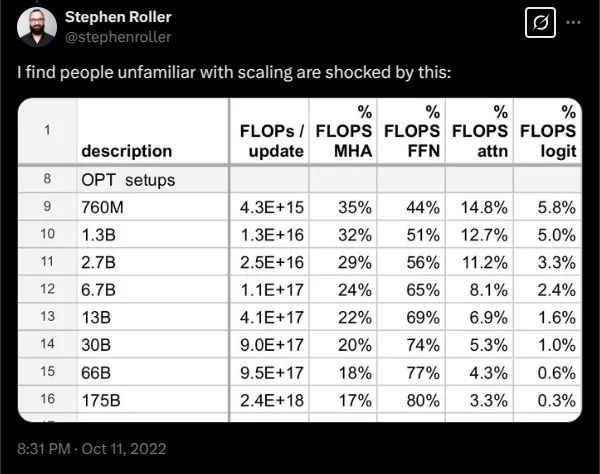
案例一:随着规模的扩大,注意力层和全连接层的计算量的比例将改变
- 小规模下 FFN 不显著
- 大规模下 FFN 主导
-
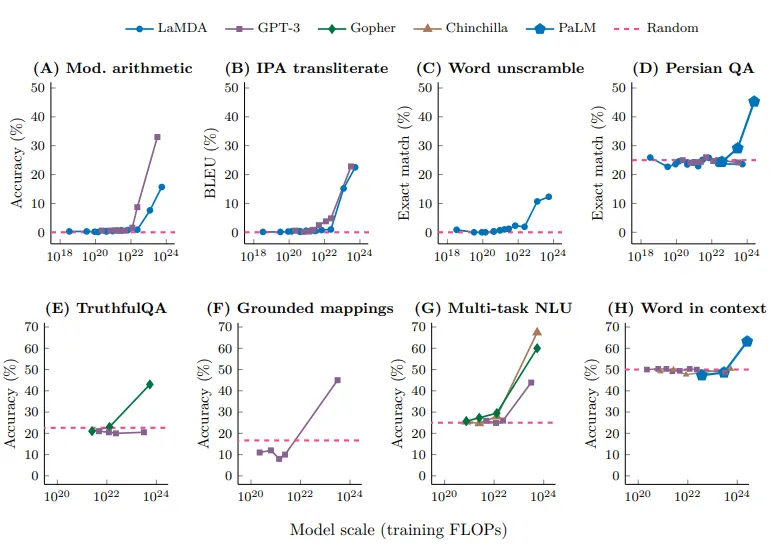
案例二:随着参数量的增加,模型能力显著提高
从这门课能学到什么?
有三方面的知识:
- 运行原理:大模型的各个部件的工作原理(例如什么是 Transformer、如何构建 GPU 上并行的模型)
- 思维模式(Mindset):旨在将硬件性能发挥到极致,并认真对待规模化问题的理念(例如,扩展定律/scaling laws)
- 实践直觉(Intuitions):凭经验判断哪些数据和建模决策能够带来良好的准确率。
惨痛的教训
有一种错误认知是:算法不重要,重要的是规模。
正确的认知应该是:可以被规模化扩大的算法最重要。
正确率=效率 x 资源。在大规模下,算法效率格外作用,因为承担不起试错成本。[2005.04305] Measuring the Algorithmic Efficiency of Neural Networks 这篇文章揭示了,在 ImageNet 上算法的不同可以带来 44x 的效能提升,远超摩尔定律带来的 11x 的硬件性能提升。
研究现状
- 基础组件
- Sequence to Sequence 建模(2014)
- Adam 优化器(2014)
- 注意力机制(2014)
- Transformer 架构(2017)
- MoE(2017)
- 模型并行技术(2018-2019)
- 早期基础模型
- ElMo:基于 LSTMs 做预训练,在下游任务上微调(2018)
- BERT:基于 Transformer 做预训练,在下游任务上微调(2018)
- Google’s T5:将所有任务都映射成 text to text 任务(2019)
- 模型规模化探索(闭源模型)
- OpenAI’s GPT-2 (1.5B):生成流畅文本,展现了初步的零样本(zero-shot)学习能力,并采取分阶段发布策略(2019)
- OpenAI’s GPT-3 (175B):展示出强大的上下文学习(in-context learning)能力,但模型闭源(2020)
- Google’s PaLM (540B):进行了更大规模的训练,但后来被认为是欠训练的(undertrained)(2022)
- DeepMind’s Chinchilla (70B):提出了计算最优的缩放定律(compute-optimal scaling laws),认为在同等算力下,应该用更多数据训练更小的模型(2022)
- 开源模型发展
- EleutherAI (The Pile & GPT-J):发布了大规模开放数据集 The Pile 和开源模型 GPT-J,推动了开源生态的发展 (2020-2021)
- Meta’s OPT (175B):尝试复刻 GPT-3,但遇到了大量的硬件挑战 (2022)
- Hugging Face / BigScience’s BLOOM:一个大型多语言开源模型,项目重点关注数据的来源和治理 (2022)
- Meta’s Llama 系列:发布了多个版本的 Llama 模型,在开源社区产生了巨大影响,成为许多后续模型的基础 (2023-2024)
- Alibaba’s Qwen (通义千问) 系列:阿里巴巴推出的一系列功能强大的开源模型 (2024)
- DeepSeek’s models (深度求索):由深度求索公司发布的一系列高性能开源模型 (2024)
- AI2’s OLMo 2:由艾伦人工智能研究所(AI2)推出的完全开放模型,包括训练数据和代码 (2024)
- 模型的开源程度
- 只开放 API,不开源模型和权重
- 开源模型、权重和技术报告,但是不开源数据集
- 开放模型、权重和数据集
- 当下最前沿的模型(2025)
- OpenAI o3
- Anthropic Claude Sonnet 3.7
- xAI Grok 3
- Google Gemini 2.5
- Meta Llama 3.3
- DeepSeek r1
- Alibaba Qwen 2.5
- Tencent Hunyuan-T1
课程总览
基础
目标:对模型全流程有一个大致了解。
在此阶段将学习分词器、模型架构和训练。与之匹配的任务一中,我们要实现 BPE 分词器、Transformer、交叉熵、AdamW 优化器和训练循环,并在特定数据集上做训练。
系统
目标:榨干硬件性能
在此阶段将学习:核函数、并行化和推理技术。与之匹配的任务二中,我们要实现融合 RMSNorm、分布式并行训练、优化器状态切分,并对实现进行性能测试和分析。
缩放定律
目标:在小规模上做实验,并据此预测大规模下的超参数和损失
问题:在给定计算量 FLOPs 的预算下,是应该使用更大的模型还是在更多的 token 上训练?
学习计算最优化缩放定律。与之匹配的任务三中,我们将定义一个 API,其能够基于之前的运行结果预测制定超参下模型的损失值。以及绘制一个曲线,拟合不同算力预算下的损失值。并给出指定预算下让损失最小的超参配置。
数据
问题:我们希望模型具备什么能力?多模态、代码、数学?这决定了我们需要什么样的数据。
与之匹配的任务四中,我们将把爬取的 html 文件转换为文本,训练分类器对文本的质量和是否有害进行分类,使用 MinHash 识别重复数据,并在置顶预算下最小化困惑度。
对齐
到此为止,我们得到的是一个基础模型,其擅长预测下一个词。但是仍需要通过对齐使得其在特定任务上表现优秀。
与之匹配的任务五中,我们将实现 SFT、DPO、GRPO。
分词器
引入
原始文本是一串使用 Unicode 编码的字符。而语言模型的输出是在一系列 token 表上的概率分布。
因此我们需要一个分词器将字符串编码为 token,以及将 token 解码为字符串。词汇表大小 vocabulary size 指的就是所有可能 token 的个数。
字符分词器 Character Tokenizer
最简单也是最符合直觉的分词器是字符分词器。每个字符都对应 Unicode 编码中的一个编号,通过查表可以将将字符串编码为 tokens。
这个方案的问题在于:
- 字符表会很大
- 很多词汇几乎不被使用,使得字符表的使用效率很低
字节分词器 Byte Tokenizer
Unicode 编码的文本可以表示为一系列字节流。在 UTF-8 编码中,每个字符都被编码为 1~4 个字节长度。使用这个方案,所有的字符串都被编码为最大 255 token 序列。
这个方案的问题在于:
- token 序列太长
- 每个 token 只能表示一个 1 字节
按词分类器 Word Tokenizer
这个分类器的思想是将字符串按照每个词进行分割,例如 "Hello world" 分为 ["Hello], " ", "world"],然后这个词集合映射到整数序列上。
这个方案的问题在于:
- 字符表是相当有限的,无法编码碰到没见过的词
- 字符表同样可能很大
字节对编码分类器 Byte Pair Encoding BPE
BPE 在 1994 被提出用来进行数据压缩,在 2015 在 NLP 中被应用到机器翻译,并在 2019 年被 GPT-2 使用。
其基本动机是使用单个 token 来表示常见的序列,使用多个 token 来表示罕见的序列。在 GPT-2 中使用词分类器将原始文本分解为一个个片段,然后在每个片段上运行 BPE 算法。
BPE 算法:将字节流视作原始 token,然后将最常出现的相邻 token 对合并。
例如:
- 初始字节流
[22, 134, 245, 22, 134, 22, 245] - 统计其中出现次数最多的相邻 token 对
(22, 134)出现两次 - 将出现最多的 token 对
(22, 134)合并并产生新 token 256 替换,得到[256, 245, 256, 22, 245] - 重复上述过程,只至达到置顶字符表大小或者没有重复的相邻字节对