本文记录了 CS336 Lab 1 的实验笔记,整个 Lab 的工作量很大,主要内容包括从头实现 BPE Tokenizer、一系列算子和基于 Transformer 的语言模型,并在此基础上进行大量的调优和消融实验。做完这个 Lab 可以对分词器的实现细节有高细粒度的理解,也能积攒对 Transformer 模型各组件的直观认识。
我的实现在 GitHub - LittleHeroZZZX/cs366 at assignment1 ,欢迎交流与指正。
Tips
提高开发效率以及避免踩坑的一些建议:
- 关闭 AI 补全(显著
提高降低效率,但是能够了解到更多的细节处理) - 使用 Python 类型标注系统,并将 Pylance 类型检查设置为标准,这样能在静态检查出绝大多数类型、参数不匹配的问题
- 实现 BPE 前首先厘清其中各个数据结构和流程的概念,例如语料库、pre-token、token、预分词,然后再动手
- 使用 logger 和 tqdm 随时随地打印进度,以便对各个组件耗时和瓶颈组件有个直观的认识
BPE 分词器
分词器的整个构建流程包括:
- 词表初始化:构造初始词表,包括 256 个 ASCII 字符和 special tokens
- pre-tokenize: 给定语料库,将语料库按照给定正则表达式划分为 pre-token,并统计词频
- 计算 BPE merges:给定 pre-token,合并出现频次最高相邻 pre-token 对作为一个 token,并不断重复这个过程直至词表达到目标
对于分词器,我将其组织为两个类:
- Pre-Tokenizer:负责将给定语料划分为 pre-token,并统计各个 pre-token 的词频
- TokenizerTrainer:基于给定词频结果运行 BPE 算法,并产出 merge pair 和 词表
Pre-Tokenizer
Pre-Tokenizer 类的接口如下所示,其对外提供一个 pre_tokenize 方法为给定字节流生成 pre-token 迭代器,一个 __call__ 方法将给定语料库文件转换为 pre-token 出现频次的字典。
|
|
在具体实现时,为了采用多进程以提高处理效率, _process_chunk 负责统计一个 chunk 中 pre-token 出现的频次。如下所示,一个语料库会被以 special token 为边界划分为多个 chunk,每个 chunk 由多篇被 special token 分隔的文档组成。
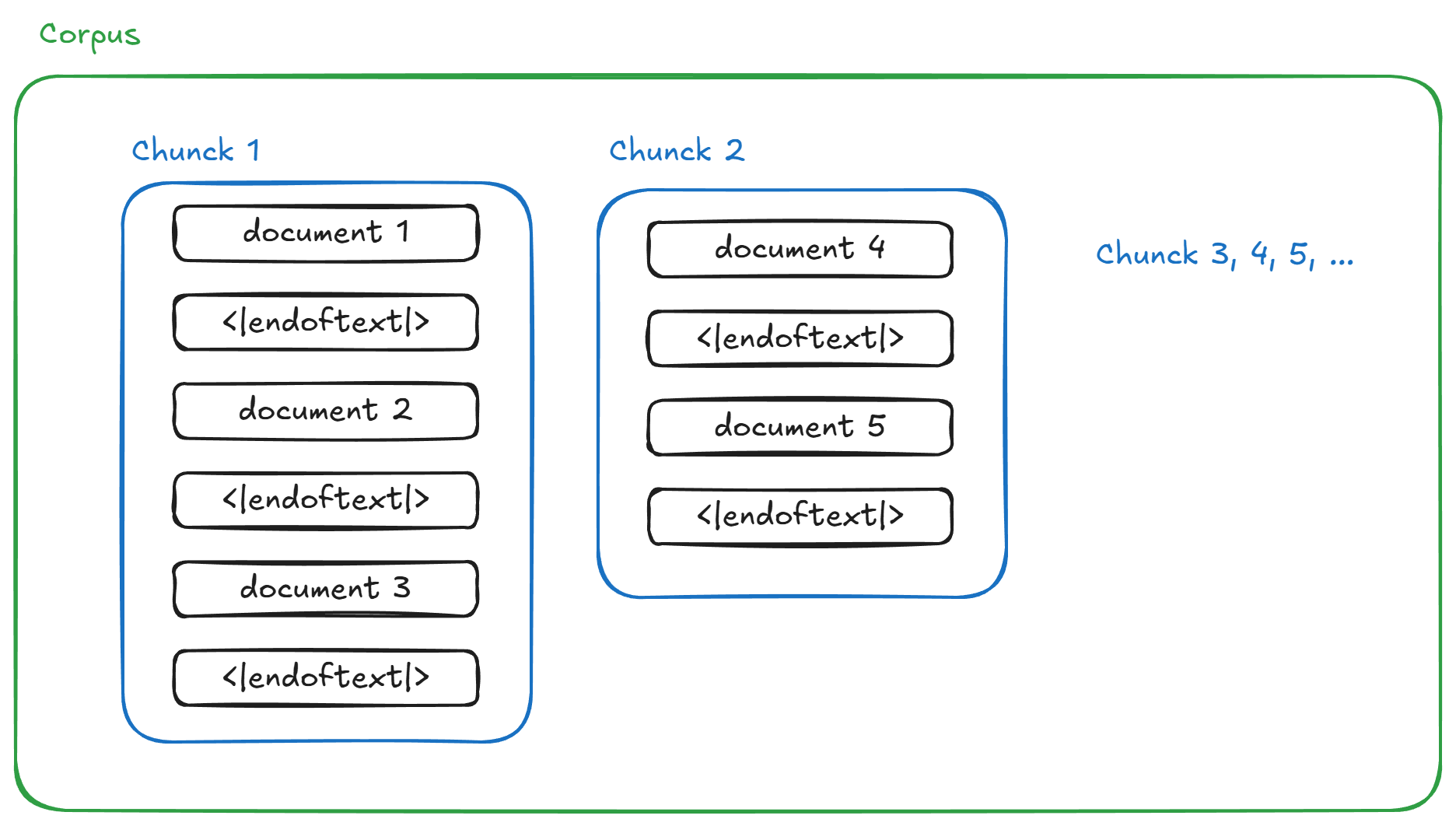
在多进程的实现中,每个进程每次处理一个 chunk。统计每个 chunk 中各个 pre-token 的出现次数,_process_chunk 先按照 special token 将 chunk 划分为 document,然后使用 Counter 模块和给定的 pre-token 的正则表达式统计单篇 document 中每个 pre-token 的出现次数。
在 _process_chunk 的帮助下,多进程的实现就变得很简单,只需将给定的语料库划分为指定数量的 chunk,然后使用进程池派发这些任务,最后将每个 chunk 的词频归约在一起即可。
参考实现:
|
|
TokenizerTrainer
TokenizerTrainer 负责在给定词频统计结果上运行 BPE 算法。BPE 算法简而言之,就是找出出现频次最高的组合并合并,为了高效实现 BEP 算法,首先要回答以下几个问题:
-
怎么初始化各个组合(Pair)的出现频次?
Pre-Tokenizer 提供的是每个 pre-token 的频次,可以通过遍历每个 pre-token 中可能出现的组合并累加频次即可。例如,对于 pre-tokenHello,可以贡献(H, e), (e, l), (l, l), (l, o), (o, 空格)这六组频次。 -
合并后怎么维护各个组合的频次?
每当一个组合被合并后,各个组合的频次需要更新,以Hello中el合并为例,需要更新的频次包括:
- 新产生组合:
el作为一个独立的 token,与其邻接的两个 token 将产生新的组合(H, el)和(el, l),这两个组合需要新增。 - 频次减少的组合:
el合并之后,这个组合不复存在,其词频需要设置为 0。除此之外,与被合并的 token 邻接的其它 token 组成的组合频次也许相应减少,即(H, e)和(l, l)的频次需要减少Hello这个单词的次数。
-
合并后如何快速定位到受影响的 pre-token?
在上一问中,我们解决了在 pre-token 已知的情况下词频的维护逻辑。但是如何快速找到受影响的 pre-token?朴素的方法是直接遍历整个 pre-token,显然每次都要遍历的方案完全不可接受。可行的方案是我们维护一张 pair 到 pre-token 的映射表,表示含有这个 pair 的 pre-token 列表。这张表在组合频次初始化时也一起被初始化,在组合被合并时也一起被更新,从而在 merge 过程中找到受影响的 pre-token 列表。 -
如何记录当前 pre-token 的状态?
pre-teken 的状态指的是当前的 pre-token 由哪些 token 组成。举个栗子,BPE 算法刚开始时,Hello这个 pre-token 的是由(H, e, l, l, o, 空格)这六个 token 组成的,在算法后期,其可能是由(Hel, l, o空格)这三个 token 组成。此时如果需要合并(l, o空格),在更新组合的频次时就要知道l的前一个 token 是啥,而非简单查询l前一个字符是什么,因此我们还需要一个字典来维护每个 pre-token 当前的状态。 -
如何获取频率最大的组合?
朴素的方案是每次都遍历整个词频表,时间复杂度是 O(n)。我们可以使用最大堆来优化这一过程,从而可以将单次获取并维护最大值的时间复杂度降为 O(log n)。
回答上述问题后,TokenizerTrainer 在训练过程中需要维护的数据结构就呼之欲出了,包括:
pair_counts:各个组合的出现频次(组合是一个两个 token 组成的元组tuple(token, token))pre_token_states:每个 pre-token 当前的状态(组成),即当前 pre-token 如何使用 token 来表示pair_to_pretokens:一个字典,表示含有指定组合的 pre-token 的 token 列表pair_heap:一个列表,用于在 Python 中实现最大堆
train
在 train 方法中,首先调用 init 方法对 pre_token_states、pair_counts、pair_to_pretokens、pair_heap 这四个数据结构进行初始化。
在主循环中获取出现次数最多的组合作为新的 token,并合并和维护上述数据结构,直至词汇表达到目标值或者没有可合并的组合。
|
|
_merge_pair
TokenizerTrainer 的核心是合并逻辑。合并算法的流程图如下所示,首先根据 Pair 获取包含合并 Pair 的所有 pre-token 列表,然后对于其中的每个 pre-token,遍历其状态(token 组成),如果是 Pair,则将 (..., A, B, ...) 替换为 (..., AB, ...),然后减少 (PrevA, A) 和 (B, NextB) 的频次,并增加 (PrevA, AB) 和 (AB, NextB) 的频次,最后设置 (A, B) 的出现频次为 0。

TokenizerTrainerC
上述 Python 版本的存在一定的性能瓶颈,所以使用 C++ 重构了 TokenizerTrainerC,核心逻辑与 Python 一致,提速十几倍,可以直接查阅代码:
- C++ 实现: cs366/assignment1-basics/csrc/tokenizer_trainer.cc at 2b4fb5a84a382aeafbd16775fcc23cba021f9831 · LittleHeroZZZX/cs366 · GitHub
- Python 接口: cs366/assignment1-basics/src/tokenization/tokenizer_trainer.py at 8afb4e7e1973a3da6f0cede46d8d35a0959f2982 · LittleHeroZZZX/cs366 · GitHub
构建 Transformer 语言模型组件
在本部分,我们需要使用基本的 Tensor 操作来构建 Transformer 各个组件模块。绝大多数组件难度不大,根据定义照抄即可。各组件实现思路:
- Linear:直接矩乘,注意权重需要转置
- Embedding:熟练运用高级索引
- RMSNorm:抄公式;为了数值稳定性,先转 float 再转回去
- SwiGLU:抄公式
- RoPE:这个难度较大,建议让 Gemini 辅助理解,强烈安利我的这份对话辅导 Gemini - 直接体验 Google AI 黑科技
- SDPA:笔者最近在 Paddle 上改造这个 API,比较熟悉,刚上手可能需要多理解一下其中的 shape 变换
- MHA:引入了 mask,同样需要熟悉这里面的 shape 变换
- Transformer LM:搭积木,注意 LM Head 后不需要 softmax
参考实现在:
- 基础组件: cs366/assignment1-basics/src/nn/basic.py at 8d800aeb4942e710ac835b1be6f89aecc0bae483 · LittleHeroZZZX/cs366 · GitHub
- 前向函数: cs366/assignment1-basics/src/nn/functional.py at 8d800aeb4942e710ac835b1be6f89aecc0bae483 · LittleHeroZZZX/cs366 · GitHub
- 网络结构: cs366/assignment1-basics/src/nn/networks.py at d0d8413fd2e8e048450d893bc648baf70cbd4258 · LittleHeroZZZX/cs366 · GitHub
训练组件
本部分需要实现损失函数、AdamW 优化器、lr schedule 和梯度裁剪。同样,需要注意的点:
- 交叉熵损失
- logits 转 float 以避免精度和溢出问题
- target(label)转 int64,使用 gather 提高效率
- SGD:抄公式
- AdamW:抄公式
- lr schedule:抄公式
- 梯度裁剪:公式中的梯度的二范数指的是所有梯度拼在一起的二范数,即如果要裁剪,则裁剪所有参数的梯度,而非分参数判断这个参数的梯度是否要裁剪
参考实现:
- 交叉熵损失:cs366/assignment1-basics/src/nn/functional.py at 8afb4e7e1973a3da6f0cede46d8d35a0959f2982 · LittleHeroZZZX/cs366 · GitHub
- 优化器: cs366/assignment1-basics/src/nn/optimizer.py at 66c38c225aa1424feb0fc95bb30153391e5ae638 · LittleHeroZZZX/cs366 · GitHub
- lr schedule 和 梯度裁剪: cs366/assignment1-basics/src/nn/utils.py at 8afb4e7e1973a3da6f0cede46d8d35a0959f2982 · LittleHeroZZZX/cs366 · GitHub
训练循环
本部分我们需要实现 Data Loader、Checkpoint 和训练循环。
Data Loader
load batch 函数就是随机对给定 dataset 按照长度 context_size 采样 batch_size 次:
|
|
Checkpoint
保存点机制可以使用 torch.save 机制来实现,需要保存的状态包括:模型状态、优化器状态和迭代步数,将他们组织成一个字段让 torch 来保存即可:
|
|
训练循环
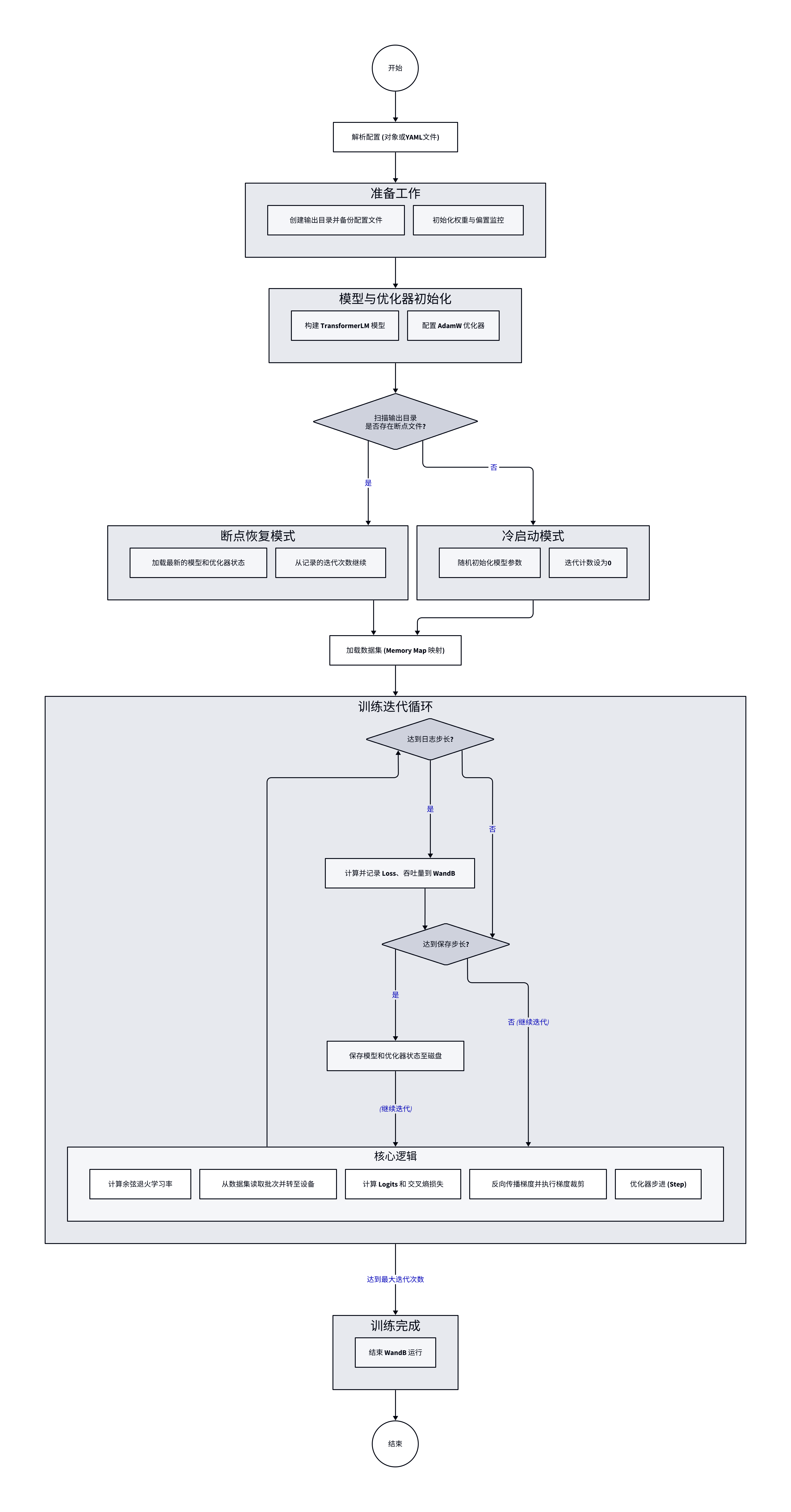
整个训练过程流程图如下所示,根据配置文件解析训练配置,初始化模型和优化器后扫描输出目录,如果存在检查点,则从断点恢复模型和优化器状态,然后使用 mmap 加载数据集。每个训练 Step 依次计算学习率、加载数据集、计算 logits 和损失、反向传播、梯度裁剪,最后优化器步进。其中,每隔指定 steps 数量,都会保存训练状态到磁盘,并使用 wandb 记录训练指标。
- 配置文件
通过使用 yaml 配置文件,可以高效地记录和管理模型的训练配置,以便后续进行大量的对比和消融实验,参考配置:
|
|
- WandB
推荐使用 WandB 自动记录实验配置和性能指标,避免手动整理记录实验数据,提升参数搜索和消融实验的效率。
train 函数参考实现在: cs366/assignment1-basics/src/nn/train.py at d0d8413fd2e8e048450d893bc648baf70cbd4258 · LittleHeroZZZX/cs366 · GitHub
生成文本
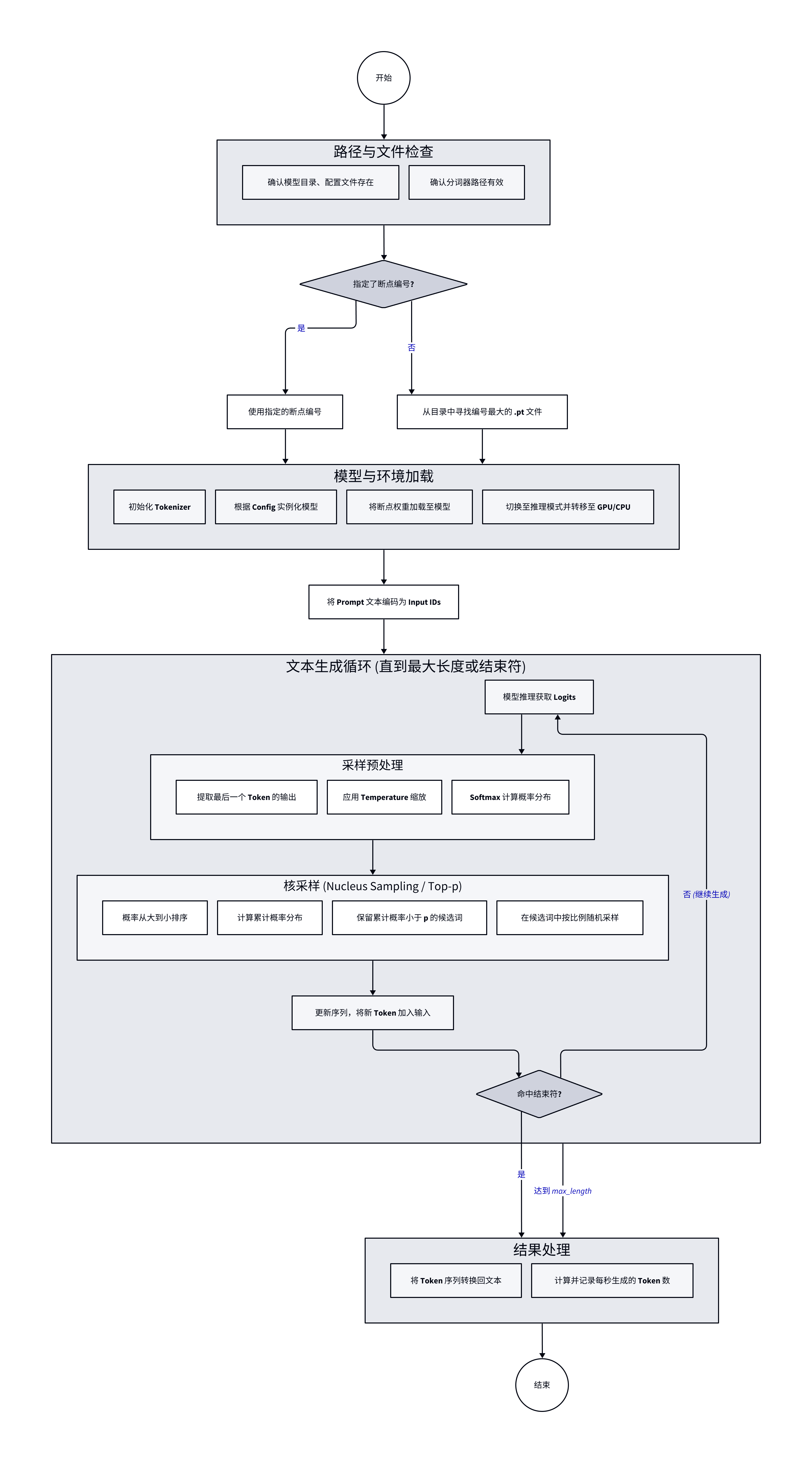
文本生成的流程图如下所示,从指定目录加载模型权重和 Tokenizer,转换为 token id 后喂给模型,获取最后一个 token 的预测结果,应用 temperature 和 softmax 后按照概率从大到小排序,保留累计概率不小于 p 的候选词,并按比例从中随机选择一个作为预测结果。预测下一轮时,将上一轮的 token 加入输入序列,重复上述过程,直至输出 endoftext 或者达到用户指定的 token 上限。
decode 参考实现在 cs366/assignment1-basics/src/nn/decode.py at d78dc879e554f47094824deadcdc2801551d0158 · LittleHeroZZZX/cs366 · GitHub